Spring Cloud Netflix
Netflix OSS is a set of frameworks and libraries that Netflix wrote to solve some interesting distributed-systems problems at scale. Today, for Java developers, it’s pretty synonymous with developing microservices in a cloud environment. Patterns for service discovery, load balancing, fault-tolerance, etc are incredibly important concepts for scalable distributed systems and Netflix brings nice solutions for these. A quick “thank-you” as well that Netflix decided to contribute to the broader open-source community with these libraries and frameworks. Other internet companies do this as well, so thank you. Some other large internet companies patent their findings and keep them closed source. And that’s just too bad.
Anyway, a lot of Netflix OSS was written at a time where things ran on an AWS cloud and there were no alternatives. A lot of assumptions about this heritage are baked into the Netflix libraries that may no longer apply based on where you’re running (ie linux containers, etc) today. With the emergence of linux containers, Docker, container management systems, etc we’re starting to see a lot of value running our microservices in linux containers (in a cloud, in a private cloud, both, etc). Additionally, because containers are basically opaque packaging of services, we tend not to care as much about what technology is really running inside them (is it Java? is it Node.js? is it Go?). Netflix OSS is for Java developers mostly. They’re sets of libraries/frameworks/configurations that need to be included in your Java application/service code.
So that brings us to point #1.
Microservices can be implemented in a variety of frameworks/languages but things like service discovery, load balancing, fault-tolerance, etc are still quite important. If we run these services in containers, we can take advantage of powerful language-agnostic infrastructure to do things like builds, packaging, deployments, health checks, rolling upgrades, blue-green deployments, security, and other things. For example, OpenShift which is a flavor of Kubernetes built with enterprises in mind, does all of these things for you: there’s nothing you have to force into the application layer that is aware or cares about these things. Keep your apps and services simple and focused on what they’re supposed to do.
So can the infrastructure help out with service discovery, load balancing and fault tolerance also? Why should this be an application-level thing?
If you use Kubernetes (or some variant), the answer is: yes.
Service discovery the Kubernetes way
With Netflix OSS you typically need to set up a service-discovery server that acts as a registry of endpoints that can be discovered with various clients. For example, maybe you use Netflix Ribbon to communicate with other services and need to discover where they are running. Services can be taken down, they can die of their own volition, or we can add more services to a cluster to help scale up. This central service-discovery registry basically keeps track of what services are available in the cluster.
One of the problems: you as a developer need to do these things:
- decide do I want a AP system (consul, eureka, etc) or an CP system (zookeeper, etcd, etc)
- figure out how to run, manage, and monitor these systems at scale (which is no trivial pet project)
Moreover, you need to find clients for the programming language you use that can understand how to speak to the service-discovery mechanism. As we’ve already said, microservices can be implemented in many different types of languages, so a perfectly fine Java client may be available, but if a Go or NodeJS client doesn’t exist, you have to write it yourself. Each permutation of language and developer may end up with their own idea of how to implement this kind of client and now you’re stuck maintaining multiple clients that try to do the same thing but in possibly semantically different ways. Or maybe each language uses its own service discovery server and has it’s own out-of-the box clients? So now you manage and maintain infrastructure for service discovery servers per language type? Either way… Yuck.
What if we just use DNS?
Well, that solves our client-library problem right? DNS is baked into any system that uses TCP/UDP and is readily available whether you deploy on premise, cloud, containers, Windows, Solaris, etc, everywhere. Your clients just point to a domain name (ie, http://awesomefooservice/) and the infrastructure knows how to route to services that DNS points to (can either be a VIP with load balancer or round-robin DNS, etc). Yay! now we don’t have to figure out what client I need to use to discover a service, I just use whatever TCP client I want. I also don’t have to figure out how to manage a DNS cluster, it’s baked into network routers and is pretty well understood.
Maybe DNS sucks for elastic discovery
The drawback: DNS kinda sucks for elastic, dynamic clusters of services. What happens when services are added to your cluster? Or taken away? The IP addresses for the services may be cached in DNS servers/routers (even some you don’t own) and even your own IP stack. What if your services/applications are listening on non-port-80 ports? DNS was made with standard ports like port 80 in mind. To use non-standard ports with DNS, you could use DNS SRV records but then you’re back to needing special clients at the application layer to discover these entries.
Kubernetes Services
Let’s just use Kubernetes. We’re gonna run things in Docker/linux containers containers anyway and Kubernetes is the best place to run your Docker containers. Or Rocket containers. Or Hyper.sh “containers”.
(Note, I’m a sucker for technology, and even more so technology that appears “simple”… because you cannot build complex systems with complex parts. You want simple parts. But making simple parts is in-itself complex. What Google and Red Hat have done with Kubernetes to simplify distributed systems deployment/management/etc is simply awesome to me 🙂 )
With Kubernetes we just create and use Kubernetes Services and we’re done! We don’t have to waste time setting up a discovery server, writing custom clients, screwing with DNS, etc. It just works and we move on to the next part of our microservice that provides business value.
So how does it work?
Here are the simple abstractions that Kubernetes brings to the table to enable this:
Pods are simple. They’re basically your linux containers. Labels are simple. They’re basically key-value strings that you can use to label your pods (eg, Pod A has labels app=cassandra, tier=backend, version=1.0, language=java). These labels can be anything your heart desires.
The last concept is Services. Also simple. A service is a fixed cluster IP address. This IP address is a virtual IP address that can be used to discover/call the actual endpoints in your Pods/containers. How does this IP address know which pods/containers are eligible to be discovered? It uses a _Label Selector__ that picks pods that have labels that you define. For example, let’s say we want a Kubernetes Service with a selector of “app=cassandra AND tier=backend”. This would give me a service with a virtual IP that discovers any pods that match that label (have both app=cassandra AND tier=backend). This selector is actively evaluated so that any pods that leave the cluster or any pods that join the cluster (based on what labels they have) will automatically start to participate in the service discovery.

Another added benefit of using Kubernetes Services for selecting pods that belong to a service is that Kubernetes is smart about which pods belong to a service with respect to its liveness and health. Kubernetes can use built-in liveness and health checking to determine whether or not a pod should be included in the cluster of pods for a specific service based on whether or not it’s alive and/or functioning properly. It can evict those that are not.
Note an instance of a Kubernetes Service is not a “thing” or an appliance or a docker container or anything..it’s a virtual “thing”… so there are no single points of failure. It’s an IP address that gets routed by Kubernetes.
This is incredibly powerful and simple for developers. Now an application that wishes to use a Cassandra backend just uses this one fixed IP address to talk to the Cassandra databases. But hard-coding a fixed IP is usually not a good idea because what if you want to move your app/service to a different environment (ie, QA, PROD, etc). Now you have to change that IP (or inject some configuration) and now you’ve added to your configuration burden. So let’s just use DNS 🙂
Using cluster DNS within Kubernetes is the right answer. Since the IP is fixed for a given environment (Dev, QA, etc) we don’t care about caching it: it’ll never change. Now if we use DNS, our app can be configured to talk to services at http://awesomefooservice/ and even when we move from Dev to QA to Prod, insofar we have those Kubernetes Services in each environment, our app doesn’t need to change.

See the above image for a visual
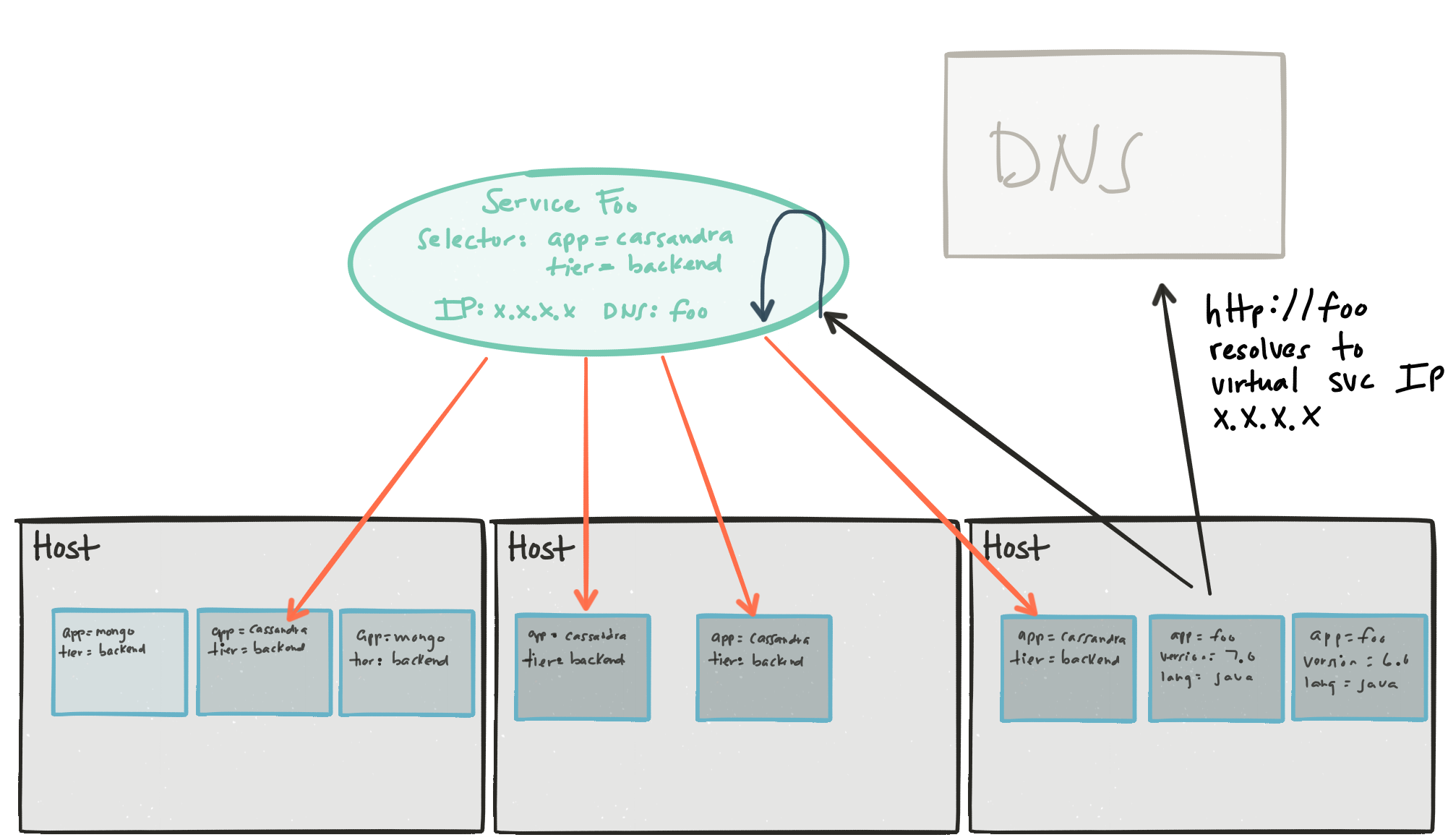{kind=link}
We don’t need additional configuration, we don’t need to worry about DNS caching/SRV records, custom library clients and managing additional service-discovery infrastructure. Pods can now be added to the cluster (or taken out of the cluster) and the Kubernetes Service’s label-selector will actively group the cluster based on the labels. Your app just talks to http://awesomefooservice/whether you’re a Java app, Python, Node.js, Perl, Go, .NET, Ruby, C++, Scala, Groovy, whatever. This service discovery mechanism doesn’t impose specific clients. Just use it.
Service discovery just got a lot easier.
What about client-side load balancing?
This one is interesting. Netflix wrote Eureka and Ribbon and with those combinations you can enable client-side load balancing. Basically what happens is the service registry (Eureka/Consul/Zookeeper/etc) is keeping track of what services exist in a cluster AND sending that data to clients that are interested in this. Then, since the client has information about what nodes are in the cluster, it can pick one (randomly, sticky, or some custom algorithm) and then call it. On it’s next call, it can pick a different service in the cluster if it so desires. The advantages here are we don’t need physical/soft loadbalancers which could quickly become a bottleneck. Another important aspect: since the client knows where the service is, the client can contact the service provider directly without additional hops.
IMHO client-side load balancing is the 5% use case. Let me explain.
What we want is a way to do scalable load-balancing ideally without any additional appliances and client libraries. In most cases we probably don’t care about the extra hop with a load balancer in the middle (think about it.. probably 99% of your apps are probably deployed this way right now). We could get into a situation where a call to service A calls service B which calls service C, and D, and E, and you get the picture. In this case if each one took an extra hop we’d incur lots of additional latency. So a possible solution could be “remove the extra hops”.. and it is… but not just in the hops to load balancers: in the number of calls you have to make to downstream services 🙂 Follow my blog on event-driven systems and the discussion around Autonomy vs Authority to see where I’m going with that 🙂
Using Kubernetes Services as we did in the Service Discovery section above, we accomplish proper load balancing (again, without all of the overhead of the service registries, custom clients, DNS drawbacks, etc). When we interact with a Kubernetes Service via its DNS (or IP), Kubernetes will by default load balance across the pods in the cluster (remember, the cluster is defined by the labels and label selectors). If you don’t want the extra hops in the load balancing, no worries; this virtual IP is routed directly to the Pods, it does not hit a physical network
Yay! Easy for the 95% use case. And chances are, you’re in the 95% distribution of use cases, so don’t need to over-engineer things. Keep it simple.
What about that 5% case? You may have a case where you have to make some business decision at runtime about which exact backend endpoint within a cluster you really want to call. Basically you want to use some custom algorithm that’s more complicated than just “round robin”, “random”, “sticky-session” and is specific to your application. Use client-side load balancing for that. In this model, you can still leverage Kubernetes’ service discovery to find out which pods are in the cluster and then use your own code to decide which pod to call directly (based on labels, etc). The Kubeflix project from the fabric8.io community has discovery plugins for using Ribbon, for example, to get a list of all the pods for a service from the Kubernetes REST API and then let users use Java code to make business decisions about which pod to call. The same thing can be done for other languages and just use the Kubernetes REST API to query the pods, etc. For these use-cases it can make sense to invest in client-specific discovery libraries. Even more appropriate is to break this custom logic into its own module so its dependencies are separate from the application. With Kubernetes, you can deploy this separate module as a sidecar to your application/service and keep the custom load balancing logic there.

Again, IMHO, this is the 5% use case and comes with additional complexity. For the 95% use case, just use what’s built in without any fancy language-specific clients.
What about fault-tolerance?
Systems with dependencies should always be built with promises in mind. This means, they should always be aware of what they’re obligation is even when dependent systems are not available or crash. Should we ask Kubernetes what it has in the way of fault tolerance?
Well, Kubernetes does have self-healing capabilities. If a pod or container within a pod goes down, Kubernetes can bring it back up to maintain its ReplicaSet invariants (basically, if you tell Kubernetes I want 10 pods of “foo” it will always try to maintain that state, even if pods go down; it will bring them back upt to maintain its replica count, in this case, 10).
Self-healing infrastructure is awesome, and comes out of the box with Kubernetes, but what we’re interested in for this discussions is what happens to an application when its dependencies (database, other services, etc) go down? Well, it’s really up to the application to figure out how it deals with that. For example, at Netflix if you try to watch a particular movie a service call is made to a “authorizations” service that knows what privileges you have for watching movies. If that service goes down should we block the user from watching that movie? Should we show exception stack traces? The netflix approach is to just let the user watch the movie. It’s better to let a subscriber watch a movie that they’re not entitled to every once in a while during a service dependency error than just blow up or say “no” when maybe they do have entitlements to that movie.
What we want is a way to gracefully degrade or look for alternative methods for keeping our promise about the contract of a service. Netflix Hystrix is a great solution for Java developers. Netflix Hystrix implements a way to do “bulkheading”, “circuit breaking”, and “fallbacks”. Each of these are application-specific impementations, so it’s justified to have specific client libraries for different languages in this case.

Can Kubernetes help with this at all? Yes!
Again, looking at the awesome Kubeflix project, you can use the Netflix Turbine project to aggregate and visualize all of the circuit breakers running in your cluster. Hystrix can expose Server Side Events as a stream that can be consumed by Turbine. But how does Turbine discover which pods have hystrix in them? Great question 🙂 We can use Kubernetes labels for this. If we label our pods that use Hystrix with hystrix.enabled=true then the Kubeflix Turbine engine can automatically discover the SSE streams for each hystrix circuit breaker and display them on the Turbine web page. Thank you Kubernetes!

Credit to Joseph Wilk for the image above.
What about configuration?
Netflix Archaius was written to handle distributed configuration management of services in the cloud. To do this, just like with Eureka and Ribbon, you set up a configuration server and use a Java library to lookup configuration values. It also supports dynamic configuration changes, etc (remember, Netflix built this for AWS.. and they’re netflix; as part of their CI/CD pipeline they would build AMIs and deploy those. Building AMIs or any VM images can be time consuming and have lots of unnecessary overhead for most cases… with Docker/linux containers, things are a bit more nimble as I’ll explain in a sec from a configuration perspective).
What about the 95% use case again? We want to have our environment-specific configurations (this is an important distinction… not “every” config is an environment-specific configuration that needs to change depending on the environment we’re running) stored outside of our applications and inject them in based on the environment (DEV, QA, PROD, etc) in which we’re running. But we really would like to have a language-agnostic way to look up the configuration and not force everyone to use Java and/or complicate their classpaths with additional Java libraries for configuration.
In Kubernetes we have three constructs for injecting environment-based configuration.
Basically we can inject configuration data to the linux containers via environment variables (which Java, NodeJS, Go, ruby, python, etc can easily read) which most languages can read. We may store our configuration in git (this is a good idea) and we could bind the configuration repo directly to our pod (as files on the file system) that can then be consumed using whatever framework facility there is for consuming application config files. Lastly, we can decouple the git repo a bit by using Kubernetes ConfigMaps to store our versioned configuration into a ConfigMap which then gets mounted as a file system into the pod. Again, you’d consume configuration files just the same way you’d consume any config file from the file-system in your respective language/framework.
What about the 5% use case?
In the 5% use case you may wish to dynamically change configuration at runtime. Kubernetes helps out with this. You can change configuration files within a ConfigMap and have those changes dynamically propogate to the pods that mount them. In this case, you’d need to have a client side library that’s capable of detecting these configuration changes and exposing them to your application. Netflix Archais has a client that can do this. Spring Cloud Kubernetes for Java makes this even easier to do within Kubernetes (using ConfigMaps).
So what about Spring Cloud?
Java folks developing microservices using Spring often equate Spring Cloud with Netflix OSS since a lot of it is based on Netflix OSS. The fabric8.io community also has lots of goodies from running Spring Cloud on Kubernetes. Please check out the https://github.com/fabric8io/spring-cloud-kubernetes for more. A lot of these patterns (including configuration, tracing, etc) can run great on Kubernetes without additional, complex, infrastructure (like service-discovery engines, config engines, etc).
Summary
If you’re looking at building microservices and you’ve gravitated toward Netflix OSS/Java/Spring/Spring Cloud, be aware that you’re not Netflix, you don’t need to use AWS EC2 primitives directly and complicate your applications by doing so. If you’re looking to use Docker, adopting Kubernetes is a wise choice and comes with lots of these “distributed-systems features” out of the box. Layering the appropriate application-level libraries where needed and avoiding over complicating your services from the beginning just because Netflix came up with this approach 5 years ago (because they had to! bet if they had Kubernetes 5 years ago, their Netflix OSS stack would look quite a bit different 🙂 ) is a wise choice 🙂